Hardware
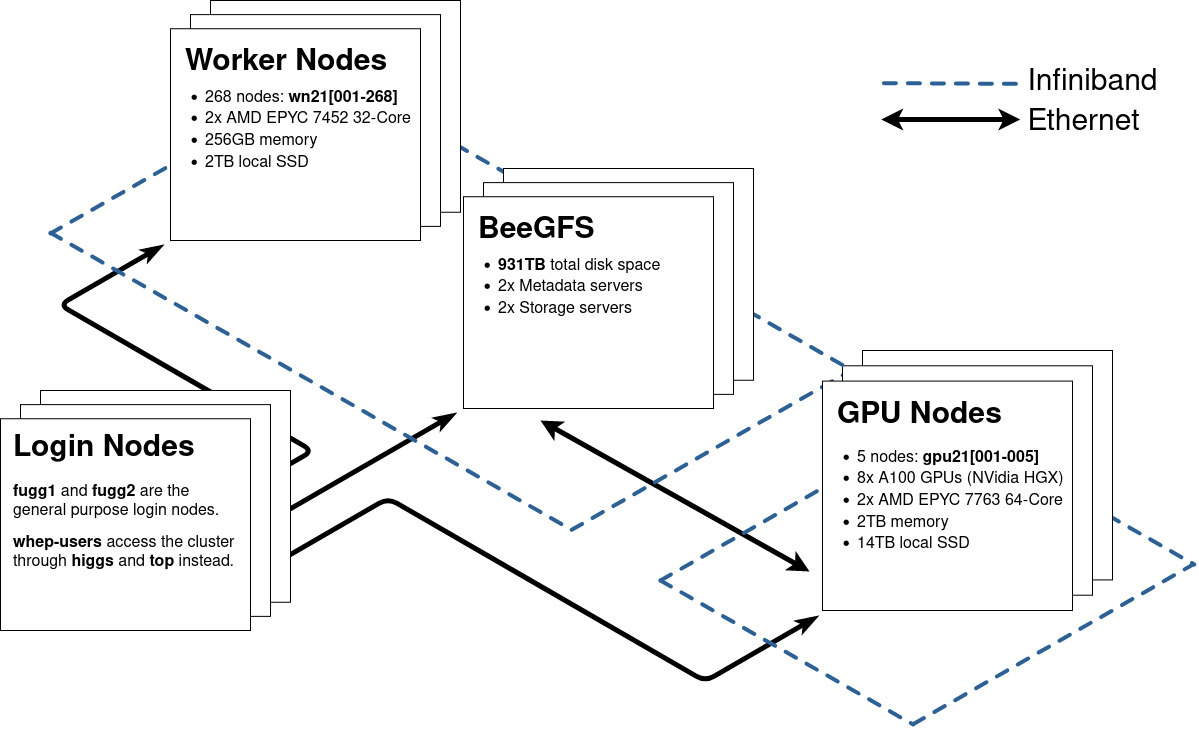
The cluster consists of 268 workernodes with 17152 Cores in total. Additionally, there are 5 GPU nodes with 8 NVidia A100 GPUs and 128 Cores each. 931 TB of parallel storage are provided with BeeGFS.
Node Types
- Login:
fugg1andfugg2: Virtual machine on Intel Xeon Gold 6238R CPUs- The fugg login nodes are intended for job submission and light interactive workloads.
- Because of architecture differences and limited resources, you should try to compile your programs through our batch system or work in interactive slurm sessions.
fugg2has infiniband-enabled access to BeeGFS
upanddown(Alma Linux 9) - only available to whep users
- wn21[001-268]:
- 2 sockets with AMD EPYC 7452 32-Core processor. 64 Cores in total
- Hyperthreading disabled
- 256GB memory, 3800MB per thread (to leave some headroom for the OS)
- gpu21[001-005]:
- 8 GPUs: NVidia HGX A100
- 2 sockets with AMD EPYC 7763 64-Core processor. 128 Cores in total
- Hyperthreading disabled
- 2TB memory, 16GB per thread
- More details here: Using GPUs
- wn19[01-08]: Intel(R) Xeon(R) Gold 6152 CPU @ 2.10GHz
- Hyperthreading enabled
- 176GB memory, 2GB per thread
Network Overview
The CPU Worker nodes wn21[001-268] are connected to each other and to the BeeGFS servers via InfiniBand and ethernet. All GPU nodes (gpu21[001-005]) are in a separate InfiniBand network and access BeeGFS via ethernet. The login nodes are currently connected to all other nodes via ethernet.
Network Performance for Computing
For network intensive computing tasks between multiple nodes (e.g. MPI), the InfiniBand (IB) network should be used in any case. Our InfiniBand network topology is a non-blocking fat tree, which allows for full bandwidth between all nodes:

Up to 40 nodes are connected with 100 Gbit/s (HDR100) to each leaf switch. All leaf switches have 40 channels with 200 Gbit/s (HDR) to the spine switches. As a consequence, it is not necessary to keep multi-node jobs physically close, since the bandwidth can be maintained throughout the whole network. Your multi-node jobs likely perform equally well with any wn21xxx combination involved.
On the other hand, an MPI job using the ethernet network could saturate parts of or the whole network, resulting in worse performance. For ethernet, the topology is similar, but with only 10 Gbit/s to each node and much fewer leaf-spine connections.